Serverless architecture is relatively new, more frequent usage started around 2014. The idea is to abstract the servers and make the execution of the apps easier. It doesn’t mean that the servers are gone, it just moves them to another level (platform) and they become part of the platform service. Computing resources get used as services without having to manage around physical capacities or limits. The dev team ideally wouldn’t care about deploying, availability, monitoring, scaling, metrics … of the applications. The team will focus mostly on the application code. Here are couple of explanations (extracted from the referenced content) about serverless architecture:
Serverless was first used to describe applications that significantly or fully depend on 3rd party applications / services (‘in the cloud’) to manage server-side logic and state.
Serverless architectures are internet based systems where the application development does not use the usual server process. Instead they rely solely on a combination of third-party services, client-side logic, and service hosted remote procedure calls (FaaS).
The essence of the serverless trend is the absence of the server concept during software development.
In this environment our application code is deployed in small parts, where every part has its own function. Many times the serverless platform is also referred as “function as a service” (FaaS). A serverless function has the ability to react on external calls (or events), by returning a response (HTML, JSON ..) or/and producing new events.
The platform is taking care of automatic scaling. When the load gets higher, the platform should be able in short time (typically in milliseconds) to deploy and start new instances (owning their own memory and processing power). Since the focus is only on the logic implementation, the deployables that are delivered by the dev teams are language specific (only compiled function). This imposes a additional constraint to the serverless platforms, to build support per language.
A typical example of deployed function:  Now if you build this kind of service, you would not care (technically) how many clients came to retrieve the product group data. The platform will scale and descale automatically, the capacity limitation of the whole system is moved to the database service.
Now if you build this kind of service, you would not care (technically) how many clients came to retrieve the product group data. The platform will scale and descale automatically, the capacity limitation of the whole system is moved to the database service.
Getting Real
While the theory sounds very exotic, the reality is not so ideal. Currently there are a couple of providers of serverless platform on the market:
- AWS Lambda (Amazon)
- Google Cloud Functions(still in alpha)
- Azure Functions (Microsoft)
- IBM OpenWhisk
The most popular and mature, comparing to the others, is the AWS Lambda. Currently the AWS Lambda supports the following languages:
- JavaScript (Node.js)
- Python
- Java
- C#
- Go
The usage of the Lambda functions comes together with AWS API Gateway. There you can configure how the function will be exposed: with URL, HTTP method, accepted URL Path parameters, HTTP Headers, response templates … A nice feature are the templates, which are using Velocity engine. They are post-processors (after the function execution is done), you can use them as view and treat the response from the function as model.
The shiny scalable system
Here is one complete system, composed of:
- Single page app (SPA) deployed on S3
- CloudFront as CDN, which uses the data from S3 as origin
- Lambda functions as backend
- DynamoDB as database service.
Client application
We chose single page app(SPA) since it brings many benefits and fits well with the whole composition.
- It’s only static files (js, css, html, images) which we can easy distribute through the CDN.
- A minimum load on our server concerning the load of application code
- There are bunch of new cool JS frameworks that can help you down the road
- You can easily achieve fancy and modern look & feel (if a designer is reading this, then it’s discussable :) )
But before jumping into it, make sure the nature of the app is right for your business needs. For example if you plan to go public with the app and you also need good search-engine ratings, then you should think again. Maybe server side rendering is a better option for you or usage of isomorphic framework. Apps like your admin portal, analytics tool, my user account, mail app … are good fit for SPA.
The backend service
Our backend logic is placed in our lambda functions. In case you decided to go with microservices, you can look at the functions as smaller pieces. A set of functions with related business logic make one microservice. The whole process of microservices design and use case separation - is not an easy thing to do. The decisions you make here can have a huge impact on:
- the time to finish your deliverables
- the system speed
- the amount of your monthly bill (badly designed microservices consume much more memory and processing power)
With this we can say that the design of your service is one of the main factors for successful project.
How to develop AWS Lambda function in Java
As we like to code in Java very often, here are few lines about it
To create a function in Java, you should use the following dependency:
groupId = com.amazonaws
artifactId = aws-lambda-java-coreCode a little bit, once you are done you can upload the jar to the AWS. Mainly goes like that. For more details check this http://docs.aws.amazon.com/lambda/latest/dg/lambda-java-how-to-create-deployment-package.html
The database
In this case we choose the DynomoDB mainly because it’s well integrated with the lambda functions and comes from the same service provider. Amazon DynamoDB is a fully managed NoSQL database service that provides fast and predictable performance with seamless scalability. Fits very well in our case. Also you can find many reviews saying that Amazon (tries to) stands behind those words.
Let’s see how it will look like:
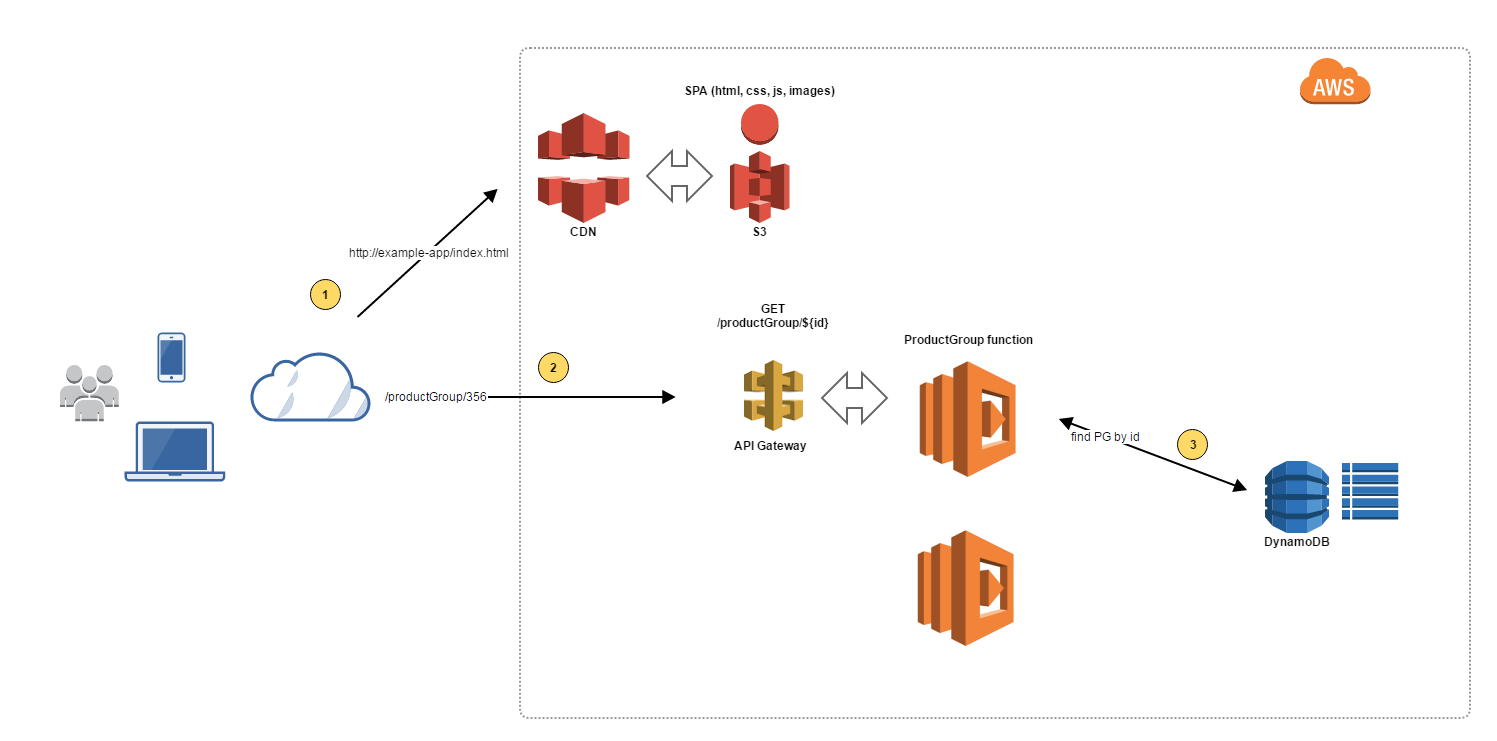
The 3 calls that are marked with yellow on the diagram, show the points where we except growth and possibly need for more capacity. Luckily we solved that with our system design. The whole application execution is outsourced to specialized services. Additionally we are not maintaining any of the shown services.
This way we can build elastic platforms which can grow and shrink quickly based on the system load. Of course, we have to keep our eyes open and monitor more closely, how many instances we are running, DB calls, response time, etc …
How serverless is different from the Container technology
The base difference is that FaaS comes with true auto-scaling, transparency and fine-grained functionality is expected as deployable item. The whole cycle of the software ideally would be done by the dev teams. This brings us to NoOps concept (which doesn’t mean that we don’t need OPS). NoOps is a movement to reduce or completely eliminate the need to manage the infrastructure requirements of an application. Instead, developers are able to deploy and scale their application without time spent installing and configuring servers, databases, and other resources. While you can also achieve the same with the containers, usually the platforms don’t offer these features, the teams should have broader knowledge, perspective and more advanced toolset.
Drawbacks
Here are the ones I consider as deal breakers for bigger projects:
- Vendor Lock-in - All the solutions and platforms are too vendor specific. There are some tools to help you deploying on different platforms, still the code itself has to support the platform conventions.
- Development - It’s hard to simulate the execution on a local environment. One thing is that the system behind the serverless platform is black-box and another thing are the missing tools, emulators, libs … that could help in this case. The developers would have to use the platform during development time, this can slower the development and also increase the expenses.
- No Server configuration - Well it should be positive thing but sometimes you can achieve excellent performance with small tuning of the server.
- (specific for AWS Lambda) Too long startup time for Java functions - It takes sometimes up to 10 seconds for a function to respond on the first request. The time is mostly spent on classloading.
References
http://martinfowler.com/articles/serverless.html
http://docs.aws.amazon.com/lambda/latest/dg/welcome.html
https://linuxacademy.com/blog/amazon-web-services-2/serverless-architecture/